
Navigating Overfitting: Understanding and Implementing Regularisation Techniques in Data Science
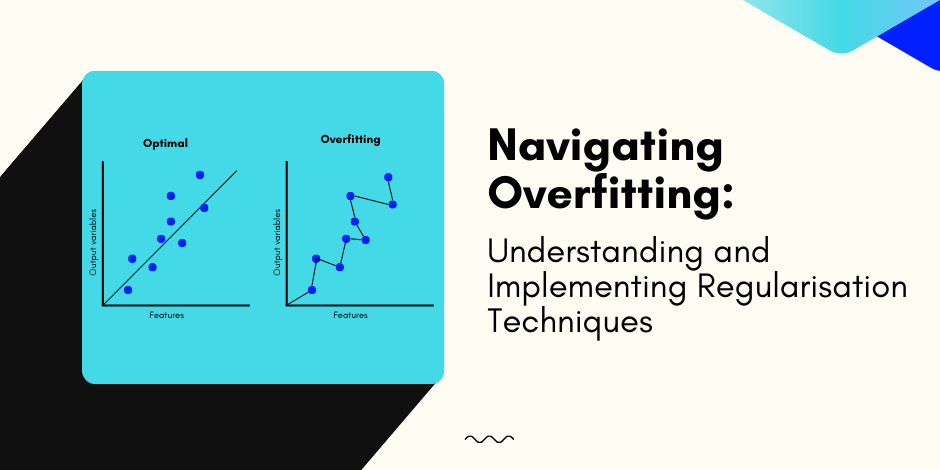
Overfitting can be a common issue with machine learning (ML) models.
When a model is overfitted, it performs on the training data but fails to generalise to new, unseen data.
This can result in poor performance and inaccurate predictions.
In this article, we will explore the concept of overfitting, its impact on models, and how to address it using regularisation techniques in data science.
Understanding the concept of overfitting

Overfitting happens when a model becomes too complex and starts to memorise the noise and randomness in the training data.
As a result, it fits the training data too closely, leading to poor performance on unseen data.
Let’s delve into the basics of overfitting.
When a model overfits, it learns the training data so well that it loses its ability to generalise to new, unseen data.
This phenomenon is akin to a student memorising the answers to specific exam questions without truly understanding the underlying concepts.
Just as the student would struggle with new questions that require knowledge application, an overfitted model falters when faced with data it has yet to see.
The basics of overfitting
Overfitting happens when the model fits the training data with such precision that it captures the noise and randomness in the data.
Over-optimising the model to the training data can lead to better generalisation and accurate predictions of new data.
The impact of overfitting on ML models
Overfitting can have severe repercussions on ML models.
It reduces the model’s ability to generalise and make accurate predictions on unseen data.
While the model may perform well on the training data, it fails to perform effectively in real-world scenarios, rendering it useless.
Identifying signs of overfitting in your model
Several common signs indicate overfitting in a model.
These signs include a significant difference in performance between training and validation data, high accuracy on training data but low accuracy on test data, and unstable performance when the training data changes.
An introduction to regularisation techniques in data science
Regularisation techniques in data science are used to mitigate the problem of overfitting in ML models.
They introduce a penalty term to the model’s objective function, discouraging it from becoming too complex.
Let’s delve into the role of regularisation in combating overfitting.
Regularisation techniques in data science are fundamental to ML and essential for building robust and generalisable models.
It plays a crucial role in addressing the common issue of overfitting, where a model performs well on training data but needs to generalise to unseen data.
ML practitioners can balance model complexity and performance by incorporating regularisation techniques in data science.
The role of regularisation in combating overfitting
The primary purpose of regularisation techniques in data science is to prevent overfitting by adding a penalty to the model’s complexity.
By doing so, regularisation encourages simpler models that are less prone to overfitting.
Regularisation techniques in data science act as a restraint, balancing model complexity and generalisation ability.
Moreover, regularisation techniques not only help in preventing overfitting but also aid in improving model interpretability.
Regularisation can enhance the transparency of models by promoting simpler models with fewer features, making it easier to understand the underlying relationships captured by the data.
Different types of regularisation techniques
Different regularisation techniques in data science are available, each with its approach to combat overfitting.
Some common types include L1 regularisation (Lasso), L2 regularisation (Ridge regression), and ElasticNet, which combines L1 and L2 regularisation.
Each type of regularisation technique has strengths and weaknesses, making it crucial for data scientists to choose the most appropriate method based on the dataset’s characteristics and the model’s specific goals.
Experimenting with different regularisation techniques in data science can help fine-tune the model’s performance and achieve optimal results.
The mathematics behind regularisation
Regularisation techniques in data science involve adding a penalty term to the model’s objective function.
This penalty term depends on the regularisation technique and imposes constraints on the model’s coefficients.
By adjusting the penalty term’s strength, we can control the trade-off between model complexity and the level of penalty imposed.
Understanding the mathematical principles behind regularisation is essential for grasping its impact on model training and performance.
It provides insights into how regularisation influences the model’s behaviour and helps make informed decisions when implementing regularisation in machine learning projects.
Implementing regularisation techniques
Now that we understand the basics of regularisation techniques in data science, let’s explore how to implement these techniques in practice.
Preparing your data for regularisation
It is crucial to preprocess and prepare your data appropriately before applying regularisation.
This includes handling missing values, scaling numerical features, and encoding categorical variables.
Applying regularisation to a machine learning model
To apply regularisation, modify the model’s objective function to include the penalty term.
You can do this by adjusting the hyperparameters of your chosen regularisation technique, such as the regularisation parameter in L1 or L2 regularisation.
Evaluating the effectiveness of regularisation
After implementing regularisation, it is essential to evaluate its effectiveness.
This involves assessing the model’s performance on the training and test datasets and comparing it to the performance without regularisation.
Various evaluation metrics, such as accuracy, precision, and recall, can be used to measure the model’s success.
Overcoming challenges in regularisation

While regularisation techniques in data science are powerful for combating overfitting, it comes with challenges.
Let’s explore some of the common obstacles faced when implementing regularisation.
Dealing with high-dimensional data
In reality, many datasets have many features, leading to high-dimensional data.
This poses a challenge in regularisation as it becomes harder to determine which features are essential for the model.
Feature selection and dimensionality reduction techniques can be employed to address this challenge.
Addressing bias-variance trade-off
Regularisation helps find the right balance between the model’s bias and variance.
However, striking this balance can be challenging.
A model with high bias may underfit the data, while a model with high variance may overfit the data.
It is crucial to experiment and fine-tune the regularisation parameters to achieve an optimal bias-variance trade-off.
Optimising regularisation parameters
Regularisation techniques often come with hyperparameters that need to be optimised.
The choice of these parameters can significantly impact the model’s performance.
Cross-validation can be employed to find your model’s optimal regularisation parameters.
Conclusion
Overfitting is a common challenge in ML models.
Regularisation techniques are powerful tools for tackling overfitting.
They add a penalty term to the model’s objective function.
By understanding the basics of overfitting, the role and types of regularisation, and how to implement it effectively, we can navigate overfitting and build more robust ML models.
Want to learn more about how to level up in data science?
As your learning partner, the Institute of Data’s Data Science & AI programme equips you with industry-reputable accreditation in this sought-after arena in tech.
We’ll prepare you with the support, resources and cutting-edge programmes needed to create a successful career.
Ready to learn more about our programmes? Contact our local team for a free career consultation.
