
What Are The 5 Steps in Data Science Lifecycle
Stay Informed With Our Weekly Newsletter
Receive crucial updates on the ever-evolving landscape of technology and innovation.
Data science is a rapidly growing field that is revolutionising the way businesses operate and make decisions.
With exciting projects like Google’s Bigtable, a robust key-value and wide-column store, businesses can leverage its capabilities for swift access to extensive sets of structured, semi-structured, or unstructured data, catering to high read and write throughput needs.
However, the success of data science projects hinges on following a well-defined and structured process known as the data science lifecycle.
In this comprehensive guide, we will explore the five key steps in the data science lifecycle and delve into the importance and key concepts associated with each step.
Understanding the data science lifecycle

The data science lifecycle is a systematic approach to extracting value from data. It provides a framework for data scientists to follow from problem definition to model evaluation.
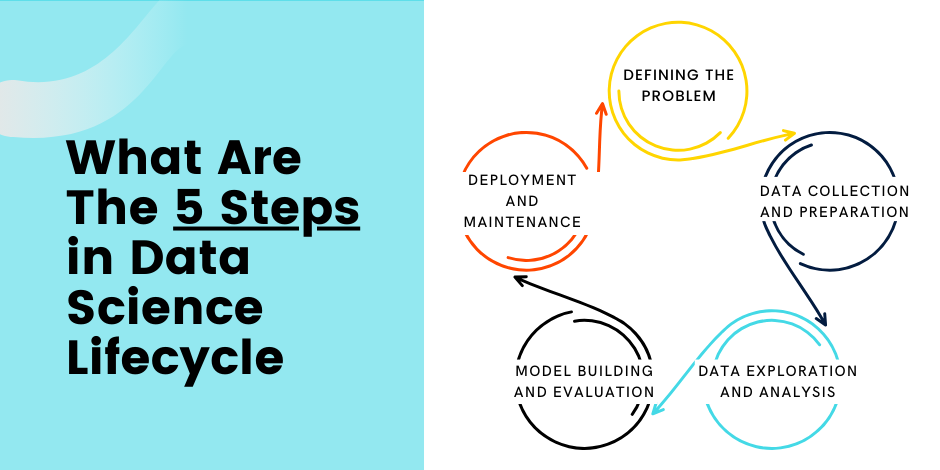
The data science lifecycle encompasses five main stages, each with its own set of tasks and goals. These stages are:
- Defining the problem
- Data collection and preparation
- Data exploration and analysis
- Model building and evaluation
- Deployment and maintenance
Step 1: Defining the problem
The first step in the data science lifecycle is to define the problem that needs to be solved.
This involves clearly articulating the business objective and understanding the key requirements and constraints.
Effective problem definition sets the stage for the entire data science project, as it helps to align the goals of the analysis with the needs of the organisation.
The role of problem definition in data science
A well-defined problem provides a clear direction for the data science project and helps data scientists focus their efforts on finding relevant and actionable insights.
Furthermore, problem definition helps to manage expectations by establishing realistic goals and timelines for the data science project.
Techniques for effective problem definition
Effective problem definition requires a systematic approach. Data scientists can employ techniques such as:
- Stakeholder interviews: Engaging with key stakeholders to understand their requirements, expectations, and pain points.
- Problem framing: Breaking down the overarching problem into smaller, more manageable sub-problems.
- Defining success criteria: Establishing clear and measurable criteria for evaluating the success of the data science project.
- Setting priorities: Identifying the most critical aspects of the problem that need to be addressed first.
- Documenting requirements: Documenting the problem statement, goals, and constraints to ensure that all team members are aligned.
Step 2: Data collection and preparation

Once the problem has been defined, the next step is to collect and prepare the relevant data for analysis. This involves identifying the data sources, acquiring the data, and transforming it into a format suitable for analysis.
The process of data collection in data science
Data collection is a critical phase in the data science lifecycle, as the quality and completeness of the data directly impact the accuracy and reliability of the analyses.
Data scientists can collect data from various sources, including internal databases, external APIs, web scraping, and surveys.
During the data collection process, it is essential to ensure the privacy and security of the data, especially when dealing with sensitive or personally identifiable information.
Data scientists must also consider data governance and compliance requirements, such as data protection regulations.
Preparing your data for analysis
Before diving into the analysis, data scientists need to prepare the data by cleaning, transforming, and restructuring it. This involves tasks such as:
- Data cleaning: Removing outliers, handling missing values, and resolving inconsistencies.
- Data integration: Combining data from different sources and resolving any discrepancies or conflicts.
- Feature engineering: Creating new features that capture relevant information and improve the performance of machine learning models.
- Data reduction: Reducing the dimensionality of the data to focus on the most informative variables.
Step 3: Data exploration and analysis
Once the data has been collected and prepared, the next step is to explore and analyse the data. This involves applying statistical techniques and data visualisation to gain insights and identify patterns and relationships.
The significance of data exploration
Data exploration is a crucial step in the data science lifecycle, as it allows data scientists to understand the characteristics and quirks of the data.
Through data exploration, they can uncover hidden insights, identify outliers or anomalies, and validate assumptions.
Data exploration also helps data scientists identify potential data quality issues or biases that may influence the analysis.
By visualising the data and conducting exploratory analyses, they can gain a holistic understanding of the dataset and make informed decisions about subsequent analyses.
Methods for thorough data analysis
Data scientists employ various methods and techniques to analyse data effectively. These methods include:
- Descriptive statistics: Calculating summary statistics, such as mean, median, and standard deviation, to summarise the data.
- Statistical modelling: Applying statistical models, such as regression or time series analysis, to uncover relationships and make predictions.
- Data visualisation: Creating charts, graphs, and interactive visualisations to present the data in a meaningful and engaging way.
- Machine learning: Using machine learning algorithms to identify patterns, classify data, or make predictions.
Step 4: Model building and evaluation
In the model-building and evaluation stage, data scientists develop and refine predictive models based on the insights gained from the previous stages.
Building a data model: what you need to know
Building a data model entails selecting a suitable algorithm or technique that aligns with the problem and the characteristics of the data.
Data scientists can choose from a wide range of models, including linear regression, decision trees, neural networks, and support vector machines.
Evaluating your data model’s performance
To evaluate the performance of a data model, data scientists employ various evaluation metrics, such as accuracy, precision, recall, and F1 score.
These metrics quantify the model’s predictive accuracy and allow for the comparison of different models or approaches.
Data scientists should also perform a thorough analysis of the model’s strengths and weaknesses.
This includes assessing potential biases or errors, determining the model’s interpretability, and identifying areas for improvement.
Step 5: Deployment and maintenance

After successfully building and evaluating the data model, the next crucial phase in the data science lifecycle is deployment and maintenance.
Deployment strategies
Deploying a data model requires careful planning to minimise disruptions and ensure its practical utility. Common deployment strategies include:
- Batch Processing: Implementing the model periodically to analyse large volumes of data in batches, suitable for scenarios with less urgency.
- Real-time Processing: Enabling the model to process data in real-time, providing instantaneous insights and predictions, ideal for applications requiring quick responses.
- Cloud Deployment: Leveraging cloud platforms for deployment, offering scalability, flexibility, and accessibility, facilitating easier updates and maintenance.
Continuous monitoring and maintenance
Once deployed, continuous monitoring and maintenance are essential to sustain the model’s performance. Key considerations include:
- Performance Monitoring: Regularly assessing the model’s accuracy and responsiveness to ensure it aligns with the expected outcomes.
- Data Drift Detection: Monitoring changes in input data distribution to identify potential shifts that might impact the model’s performance.
- Updating Models: Periodically updating the model to incorporate new data, adapt to changing patterns, and improve predictive capabilities.
- Security Measures: Implementing robust security measures to protect the model and data, especially when dealing with sensitive information.
Conclusion
By following the five steps outlined in the data science lifecycle, organisations can harness the power of data to drive innovation, make informed decisions, and gain a competitive edge.
The data science lifecycle provides a structured and systematic approach that ensures the rigour, transparency, and reliability of data science projects.
So, whether you are a seasoned data scientist or just starting your journey, embracing the data science lifecycle will set you on the path to success.
If you’re interested in pursuing a career in data science, you may want to explore Institute of Data’s 3-month full-time or 6-month part-time Bootcamps.
To find out more about our programmes led by industry professionals, you can download a Data Science & AI Course Outline.
